[Data] Apache Pinot 소개
Apache Pinot 소개
Apache Pinot
유저 지향 분석 업무를 낮은 지연, 높은 처리량 분석 제공을 위한 실시간 분산 OLAP(On-Line Analytical Processing) 데이터 저장소
두 유형의 데이터를 기반으로 데이터 구축함.
- 스트림 데이터 : Apache Kafka, Amazon Kinesis
- 배치 데이터 : Hadoop HDFS, Amazon S3, Azure ADLS, Google Cloud Storage
매우 낮은 지연 시간의 분석을 제공하며, 많은 요청에서도 낮은 지연 시간으로 분석 데이터 제공 가능.
피놋의 다양한 인덱싱 및 사전 집계 기술 덕분에 column 구조의 데이터 저장이 가능.
스케일 업, 아웃 가능.
일관된 성능 제공.
이런한 기능들 덕분에 유저 또는 다양한 경우의 실시간 분석 제공에 Apache Pinot이 적합.
(내부 대시보드, 이상 탐지, 임시 데이터 탐색 등)
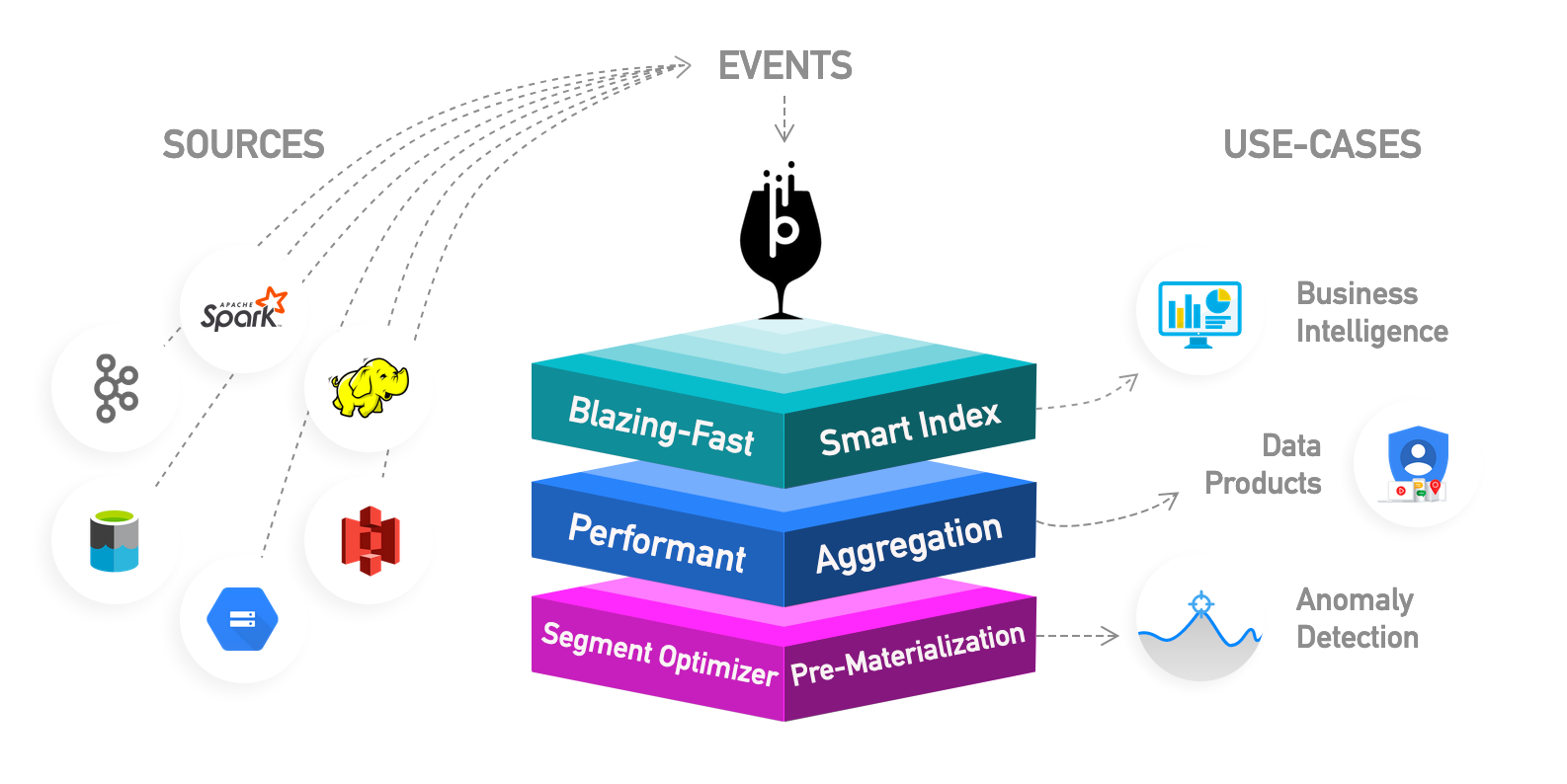
Apache Pinot 특징
- 컬럼 기반 데이터 베이스
- 다양한 인덱싱 지원
- 쿼리 최적화
- 스트림과 배치 데이터 ingest
- SQL 기반 쿼리
- real-time ingestion 하면서 upsert
- Kubernetes 기반 clous-native 배포 가능
유저 지향 실시간 분석
유저 지향 실시간 분석이란 최종 유저에게 제공되는 분석을 의미함. 즉, 유저가 늘어날 수록 query의 양도 증가하며, 모든 유저에게 개인화된 분석을 제공할 수 있어야 함. Pinot은 일 초 이내로 데이터 처리가 가능함. 이러한 기능을 제공하기 위해 요구되는 사항은 아래와 같음.
- 최신의 데이터 : 시스템은 최신의 데이터를 실시간으로 받아 처리하여, 쿼리까지 할 수 있어야 함.
- 높은 속도와 차원의 이벤트 데이터 지원. 다양한 액션과 소스로부터 받을 수 있음.
- 낮은 처리 대기 시간
- 확장성
- 낮은 비용
왜 Pinot인가?
- 유져 지향 실시간 분석 제공
- 사업 지표를 위한 실시간 대시 보드
- Pinot은 대규모 다차원 데이터에 대해 slice, dice, drill down, roll up, pivot과 같은 일반적인 분석 작업 수행
- BI 툴인 Superset, Tablueau, PowerBI를 통해 시각화 가능
- Enterprise business intelligence : 빅데이터와 전통적인 데이터 웨어하우스의 역할을 합쳐 분석 및 보고 기능을 제공
- Enterprice application development : 애플리케이션 개발자는 Pinot을 통해 kafka와 같은 스트리밍 데이터에 대해 SQL을 사용하여 집계 저장소로 활용할 수 있음. 다양한 데이터에 대한 집계 가능.
실시간 OLAP 데이터베이스 비교 : Apache Pinot vs Apache Druid vs ClickHouse
- 해당 비교는 2023년 4월 18일 아티클 기준이며, Apache Pinot 개발사 입장의 아티클이기 때문에 이 점 참고가 필요할 듯
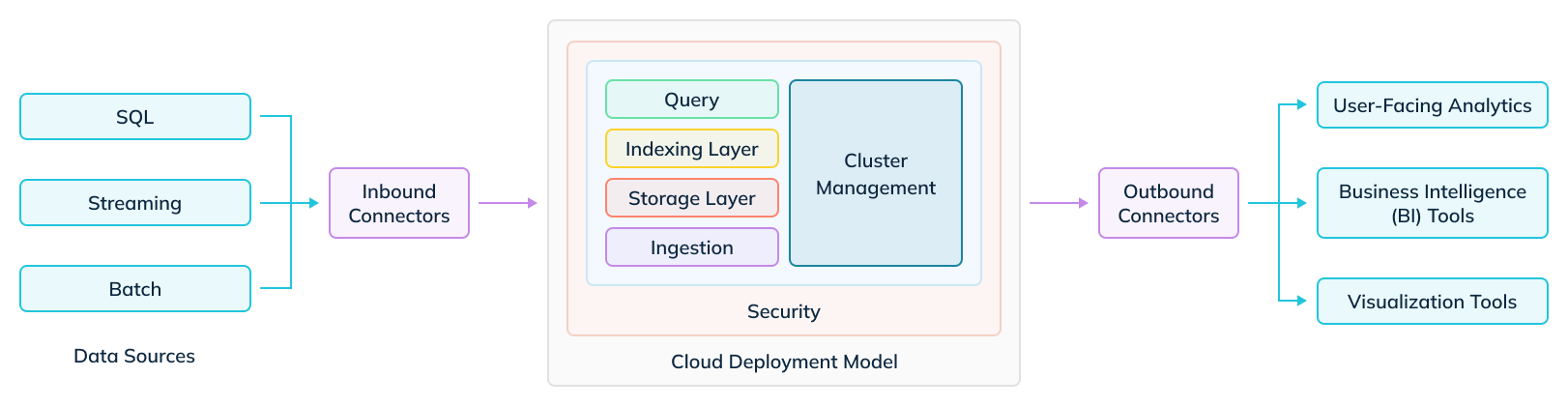
일반적인 OLAP 데이터 베이스 layer 구조
비교 요약
1) Apache Pinot
장점
- 인덱싱 전략, 데이터 레이아웃 기술을 통한 뛰어난 성능
- 실시간 스트림과 배치 데이터 통한 데이터 ingestion
- upsert 실시간 지원
- 멀티 테넌시 지원 : 단일 시스템으로 멀티 유저 지원
- 클라우드 배포
개선점
- 데이터 타입 지원
- BI 통합을 위한 outbound connector
- 일부 보안 개선점
2) Apache Druid
장점
- 동일하게 실시간과 배치 데이터 소스
- 데이터 ingestion 동안 데이터 사전 처리 지원이 뛰어남
- 유연한 SQL 기반 insestion 방식
개선점
- upsert 실시간 지원하지 않음
- 실시간 push/write 미지원
- 제한적인 인덱싱 기능
- 클라우드 기반 티어 저장소 미지원
3) ClickHouse
장점
- 단순한 구조로 구축하기 가장 쉬움
- 다른 모델보다 실시간 push 모델 좋음
- 데이터 타입
- outboud connector : pinot이 제공하지 못하는 grafana도 제공
개선점
- 실시간 원천으로부터 데이터 pulling
- 제한적인 인덱싱
- 단일 노드 배포는 쉬우나, 확장이 어려움
- 운영 복잡성
- 분산 쿼리 라우팅, 복제/수집/노드 관리와 같은 클러스터 관리 작업 수동 설정 필요
