[데이터 중심 애플리케이션 설계] 4장. 부호화와 발전
4장. 부호화와 발전
4장의 핵심 내용
- 인코등 다양한 형식
- 메시지 전달 시스템과 데이터 인코딩 형식 -> 데이터 저장 및 통신에서의 사용 방법
상위 호환성 : 새로운 코드는 예전 코드가 기록한 데이터를 읽을 수 있어야.
하위 호환성 : 예전 코드는 새로운 코드가 기록한 데이터를 읽을 수 있어야.
1. 데이터 부호화 형식
부호화(직렬화) : 인메모리 표현 -> 바이트열
복호화(파싱, 역직렬화) : 바이트열 -> 인메모리 표현
1.1 언어별 형식
각 언어 별 직렬화 기능 내장되어 있음.
- 언어 내장 부호화 라이브러리 문제점
- 특정 언어와 강결합 : 다른 언어와의 통합 시 어려움 존재
- 보안 : 바이트 복호화 시 보안 관련 문제 발생 가능성 존재
- 상, 하위 호환성 떨어짐
- 효율성 : 성능 떨어지는 경우 많음.
1.2 JSON, XML, 이진변형
JSON
- 문자열, 수 구분.
- 정수, 부동소수점 수 구별 X, 정밀도 지정 불가
- 2^53 보다 큰 정수 부정확해질 가능성 존재
- 유니코드 문자열 지원. 이진 문자열 지원 X
- 스키마 지원
XML
- 복잡한 형식
- 수, 숫자(digit) 문자열 구분 불가
- 유니코드 지원. 이진 문자열 지원 X.
- 스키마 지원
CSV
- 수, 숫자(digit) 문자열 구분 불가
- 스키마 X
- 모호한 형식 : 값이 쉼표, 개행문자 포함 경우 난감;;
이진 부호화
JSON과 XML은 간단. 허나 공간에 있어 이진 형식보다 큼. 이진 부호화가 크기, 파싱 속도에 있어 효율적. but, 가독성과 크기 간의 트레이드 오프는 고민 지점.
스리프트 & 프로토콜 버퍼
이진 부호화 라이브러리 스리프트, 프로토콜 버퍼 모두 스키마 필요. 기존 이진 부호화와 달리
필드 태그존재 스키마의 required, optional 정보에 대한 부호화 X. 실행 때 확인
- 스리프트
- 두 가지 방식
- 바이너리 프로토콜 : 필드 이름 없음, 대신 필드 태그 존재
- 컴팩트 프로토콜 : 34 바이트 부호화. 가변 길이 정수 사용.
struct Person { 1 : required string userName, 2 : optional i64 favoriteNumber, 3 : optional list<string> interests }
- 두 가지 방식
- 프로토콜 버퍼
- 33 바이트
message Person { required string user_name = 1; optional int64 favorite_number = 2; repeated string interests = 3; }
- 33 바이트
필드 태그와 스키마 발전
필드추가
- 새로운 태그 번호 부여 -> 상위호환성 유지
- 추가 필드 optional or default 값 설정 -> 하위 호환성 유지
필드 수정
- 필드명 수정 가능, 필드 태그 수정 불가
필드 삭제
- optional 필드만 삭제 가능
- 같은 태그 번호 재사용 불가
데이터 타입과 스키마 발전
프로토콜 버퍼 : repeated 표시자
스리프트 : 전용 목록 데이터 타입
1.3 아브로(AVRO)
- 또 하나의 이진 부호화 형식
- 스키마 사용. 두 개의 스키마 언어 존재(아브로 IDL, JSON 기반)
- 스키마에 태그 번호 없음.
- 모든 부호화 중 길이가 가장 짧음
- 바이트열 내 필드, 데이터 타입 식별 위한 정보 없음.
아브로 IDL
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
JSON 표현
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null", "long"], "default": null},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
쓰기 스키마 & 읽기 스키마
쓰기 스키마 : 네트워크 전송. 파일, DB에 write. 스키마 버전 사용해 데이터를 아브로로 부호화할 때 사용 하는 스키마.
읽기 스키마 : 네트워크 수신. 파일, DB read. 특정 스키마로 복호화할 때 사용 스키마.
아브로의 핵심 아이디어는 쓰기 스키마와 읽기 스키마가 동일하지 않아도 되며 단지 호환 가능하면 됨.
- 아브로 데이터 복호화 과정 : 쓰기 스키마, 읽기 스키마 모두 읽고, 쓰기 스키마에서
읽기 스키마로 데이터 변환. - 필드 순서 상관 없음 : 필드명으로 매핑하기 때문
- 읽기 스키마 X & 쓰기 스키마 O : 해당 필드 무시
- 읽기 스키마 O & 쓰기 스키마 X : 읽기 스키마 디폴드 값 할당
스키마 발전 규칙
- 상위 호환성 : 새로운 버전의 쓰기 스키마와 예전 버전의 읽기 스키마
- 하위 호환성 : 새로운 버전 읽기 스키마와 예전 버전의 쓰기 스키마
호환성 유지 위해 기본 값이 있는 필드만 추가, 삭제 가능
if1) 기본 값 없는 필드 추가 -> 새로운 읽기는 예전 쓰기 기록 데이터 읽기 불가. : 하위 호환성 X
if2) 기본 값 없는 필드 삭제 -> 예전 읽기는 새로운 쓰기 데이터 읽기 불가 : 상위 호환성 X
아브로의 경우 필드에 null을 허용하려면 유니온 타입(union type)을 사용. 프로토콜 버퍼, 스리프트의 optional, required 표시자 없음.-> union type, 기본 값으로 대체
아브로는 타입 변경 가능. 필드 이름 변경 가능.
이름 변경 시 필드 이름 별칭 통해 해결.
쓰기 스키마
읽을 때 쓰기 스키마 어떻게 확인?
- 많은 레코드가 있는 대용량 파일 : 파일 시작 부분에 한 번만 쓰기 스키마 포함
- 개별적으로 기록된 레코드 소유 DB : 레코드 시작 부분 스키마 버전 정보 포함. DB에 별도 스키마 버전 관리.
- 네트워크 연결을 통해 레코드 보내기 : 스키마 버전 합의
동적 스키마 : 아브로 장점
프로토콜 버퍼, 스리프트와 달리 스키마에 태그 번호 미포함. => 동적 생성 스키마에 더 친숙.
필드는 이름으로 식별되어 아브로 스키마 생성 후 신경쓰지 않아도 됨.
스키마 장점
프로토콜 버퍼, 스리프트, 아브로는 스키마 사용 이진 부호화 형식 기술.
- XML 스키마, JSON 스키마보다 간단 + 더 자세한 유효성 검사 규칙 제공.
- 구현과 사용 더 간단. 광범위 프로그래밍 언어 지원
2. 데이터플로 모드
2.1 데이터베이스
데이터베이스에 기록하는 프로세스는 데이터를 부호화하고 데이터베이스에서 읽는 프로세스는 데이터를 복호화.
상하위 호환성 모두 필요.
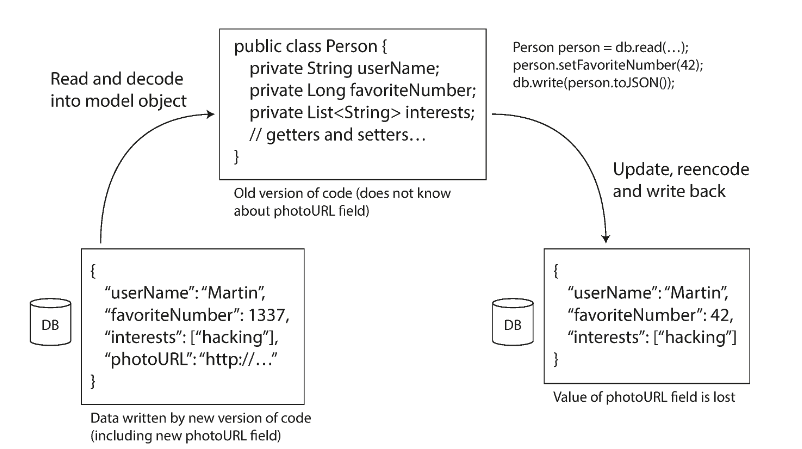
- DB 새 컬럼 추가 & 애플리케이션은 모름 : 애플리케이션이 DB 레코드 변경 시 데이터 유실 가능성 존재
마이그레이션을 진행하던가, 혹은 null을 기본값으로 세팅하여 새로운 컬럼 추가 허용하는 방식으로 해결. (MySQL은 ALTER TABLE 시 전체 테이블을 복사하기 때문에 다른 RDB와는 다름)
데이터 덤프의 경우 최신 스키마를 사용해 부호화. 한 번에 기록하고 이후에는 변하지 않기 때문에 아브로 객체 컨테이너 파일과 같은 형식이 적합
2.2 서비스
서버와 클라이언트가 사용하는 데이터 부호화는 서비스 API의 버전 간 호환이 가능해야 한다.
REST와 RPC는 하나의 프로세스가 네트워크를 통해 다른 프로세스로 요청을 전송하고 가능한 빠른 응답을 기대하는 방식.
웹서비스
기본 프로토콜로 HTTP 사용하는 서비스.
웹서비스 두 가지 방식
- REST
- 프로토콜 X. HTTP 원칙 토대 설계 철학.
- SOAP
- 네트워크 API 요청을 위한 XML 기반 프로토콜.
- Web Service Description Language, XML 기반 언어 사용해 기술.
- WSDL : 클라이언트가 로컬 클래스와 메서드 호출을 사용해 원격 서비스에 접근하는 코드 생성 가능
- 정적 타입 프로그래밍 언어에 적합. but, 동적 타입 언어 유용성 떨어짐
- 다른 벤더 간 상호운용성 문제 존재
원격 프로시저 호출(RPC) 문제
RPC 모델은 원격 네트워크 서비스 요청을 같은 프로세스 안에서 특정 프로그래밍 언어의 함수나 메서드를 호출하는 것과 동일하게 사용 가능하게 해줌.
예측이 어렵다는 한계 존재 + 실패에 대한 재요청 대책 필요.
- timeout
- 재처리 시 멱등성 보장
- 로컬 호출보다 느리고 지연 시간 다양
- 네트워크 전송을 위한 바이트열 부호화 과정 필요
- 다른 언어간의 호환성 조심해야 함
RPC 현재 방향
REST 상에서 JSON 같은 부류의 프로토콜보다 이진 부호화 형식을 사용하는 RPC 프로토콜이 우수한 성능 제공할 수도 있음. 하지만 RESTful API는 실험/디버깅 적합, 주요 언어/플랫폼 지원, 다양한 도구 생태계 장점 존재.
RPC 프레임워크의 주요 초점은 보통 같은 데이터센터 내의 같은 조직이 소유한 서비스 간 요청에 있음.
2.3 메시지
메시지를 직접 네트워크 연결로 전송하지 않고 임시로 메시지를 저장하는 메시지 브로커를 거쳐 전송.
장점
- 수신자가 사용 불가 또는 과부하 상태여도 메시지 브로커가 버퍼처럼 동작 : 시스템 안정성 향상
- 메시지 유실 방지 : 죽었던 프로세스에 메시지 다시 전달 가능
- 송신자가 수신자의 IP 주소, 포트 번호 몰라도 됨
- 하나의 메시지를 여러 수신자 전송 가능
- 송신자와 수신자의 논리적 분리
분산 액터 모델
단일 프로세스 안에서 동시성을 위한 프로그래밍 모델.
스레드를 직접 처리하는 대신 로직이 액터에 캡슐화.
보통 각 액터는 하나의 클라이언트나 엔티티 나타냄.
액터는 로컬 상태를 가질 수 있고 비동기 메시지의 송수신으로 다른 액터와 통신.
액터는 메시지 전달을 보장하지 않아, 유실 가능성 존재.
각 액터 프로세스는 한 번에 하나의 메시지만 처리 -> 스레드 고려 필요 없음. 각 액터는 프레임워크와 독립적으로 실행 가능.
