[데이터 중심 애플리케이션 설계] 11장. 스트림 처리
11장. 스트림 처리
스트림 처리 : 매 초가 끝나는 시점에 1초 분량의 데이터 처리 or 고정된 시간 조각이라는 개념을 완전히 버리고 단순히 이벤트가 발생할 때마다 처리하는 방식
스트림? 시간 흐름에 따라 점진적으로 생산된 데이터
1. 이벤트 스트림 전송
이벤트
- 스트림처리 문맥에서의 레코드
- 특정 시점에 일어난 사건에 대한 세부 사항 포함
- 일반적으로 이벤트 발생 타임스탬프 포함
- 텍스트 문자열, JSON, 이진 형태 등으로 부호화
- 프로듀서가 만든 이벤트에 대해 여러 컨슈머가 처리 가능
- 토픽이나 스트림으로 관련 이벤트를 묶음
- db에 데이터 저장 후 소비자가 지속적 폴링 방식은 오버헤드가 큼 -> 이벤트가 발생할 때마다 소비자에게 알리는 방식이 더 효율적
1.1 메시징 시스템
새로운 이벤트에 대해 소비자에게 알려주려고 쓰이는 일반적인 방식
다수의 생산자 노드가 같은 토픽으로 메시지를 전송. 다수의 소비자 노드가 토픽 하나에서 메시지 수신.
발행/구독 모델 메시징 시스템 구분한는 두 가지 질문
- 생산자가 소비자가 메시지를 처리하는 속도보다 빠르게 메시지 전송하는 경우
- 메시지 버리기
- 큐에 메시지 버퍼
- 배압
- 노드가 죽거나 일시적으로 오프라인이 된다면 손실되는 메시지가 있을까?
생산자 -> 소비자 메시지 직접 전달
예시)
- UDP 멀티 캐스트 : 낮은 지연.
- ZeroMQ(브로커 X 메시지 라이브러리), nanomsg : TCP 또는 IP 멀티캐스트 상 발행/구독 메시징 구현
- StatsD, BruBeck : UDP 메시징 사용
- Webhook : 이벤트 발생할 때마다 콜백 URL 요청
메시지가 유실될 가능성 존재 ~> 애플리케이션 코드 작성 시 유의해야 함.
직접 메시징 시스템은 일반적으로 생산자와 소비자가 항상 온라인 상태 가정 => 생산자 또는 소비자 오프라인 시 메시지 유실 가능성 존재
메시지 브로커
- 직접 메시징 시스템의 대안.
메시지 큐라고도 함. - 생산자는 브로커로 메시지를 전송. 소비자는 브로커에서 메시지를 수신.
- 지속성 문제 해결 : 데이터 저장을 브로커가 담당. 브로커의 클라이언트 상태 변경(접속, 접속 해제, 장애)에 쉽게 대처 가능
- 비동기 : 소비자는 생산자와 상관 없이 브로커의 큐 대기만 확인하고 소비하면 됨
메시지 브로커 vs 데이터 베이스
| 메시지 브로커 | DB | |
|---|---|---|
| 메시지 생애 주기 | 소비자 데이터 배달 성공 후 메시지 삭제 | 데이터 삭제 요청 때 삭제 |
| 큐 크기 | 작음 | |
| 데이터 조회 | 특정 패턴과 부합하는 토픽의 부분 집합 구독 | 보조 색인 등 다양한 방법 존재 |
| 데이터 조회 결과 | 데이터 변경 시(새로운 메시지 생성) 클라이언트에 전달 | 질의 시점 스냅샷 |
복수 소비자
주요 패턴 두 가지
- 로드 밸런싱
- 각 메시지는 소비자 중 하나로 전달
- 브로커는 메시지를 전달할 소비자를 임의로 지정
- 처리 병렬화 목적 소비자 추가하고 싶을 때 유용
- 팬 아웃
- 각 메시지는 모든 소비자에게 전달
- 여러 독립적인 소비자가 브로드캐스팅된 동일한 메시지를 서로 간섭 없이 청취
두 가지 패턴 함께 사용 가능.
eg) 두 개의 소비자 그룹에서 하나의 토픽을 구독하고 각 그룹은 모든 메시지를 받지만 그룹 내에서는 각 메시지를 하나의 노드만 받게 함.
확인 응답과 재전송
메시지 손실을 방지하기 위해 메시지 브로커는 확인 응답 사용.
클라이언트는 메시지 처리가 끝았을 때 브로커가 메시지를 큐에서 제거할 수 있게 브로커에게 명시적으로 알려야 함.
- 만약 브로커 확인 응답 받기 전 클라이언트로의 연결 닫히거나 타임아웃 발생 시 : 브로커는 메시지 미처리 가정 -> 다른 소비자에게 재전송
로드 밸런싱 + 재전송 조합 : 메시지 순서에 영향
- 메시지1 전송 후 소비자 장애 발생.
- 메시지2 처리 후 재전송된 메시지1 소비 : 메시지2 -> 메시지1 순서로 이벤트 처리됨
- 해결 방안 : 소비자마다 독립된 큐 사용.(= 로드 밸런싱 미사용)
1.2 파티셔닝된 로그
브로커는 메시지를 일시적으로 보관하는 개념.
브로커는 확인 응답을 받으면 메시지 삭제. 이미 받은 메시지는 복구 불가.
데이터베이스의 지속성 있는 저장 방법 + 메시징 시스템의 지연 시간이 짧은 알림 기능 = 로그 기반 메시지 브로커
로그를 사용한 메시지 저장소
생산자가 보낸 메시지는 로그 끝에 추가하고 소비자는 로그를 순차적으로 읽어 메시지 수신.
파티셔닝 : 처리량 높이기 위한 확장 방법으로 로그를 파티셔닝.
토픽 : 같은 형식의 메시지를 전달하는 파티션들의 그룹
오프셋 : 각 파티션 내 모든 메시지에 부여되는 단조 증가하는 순번
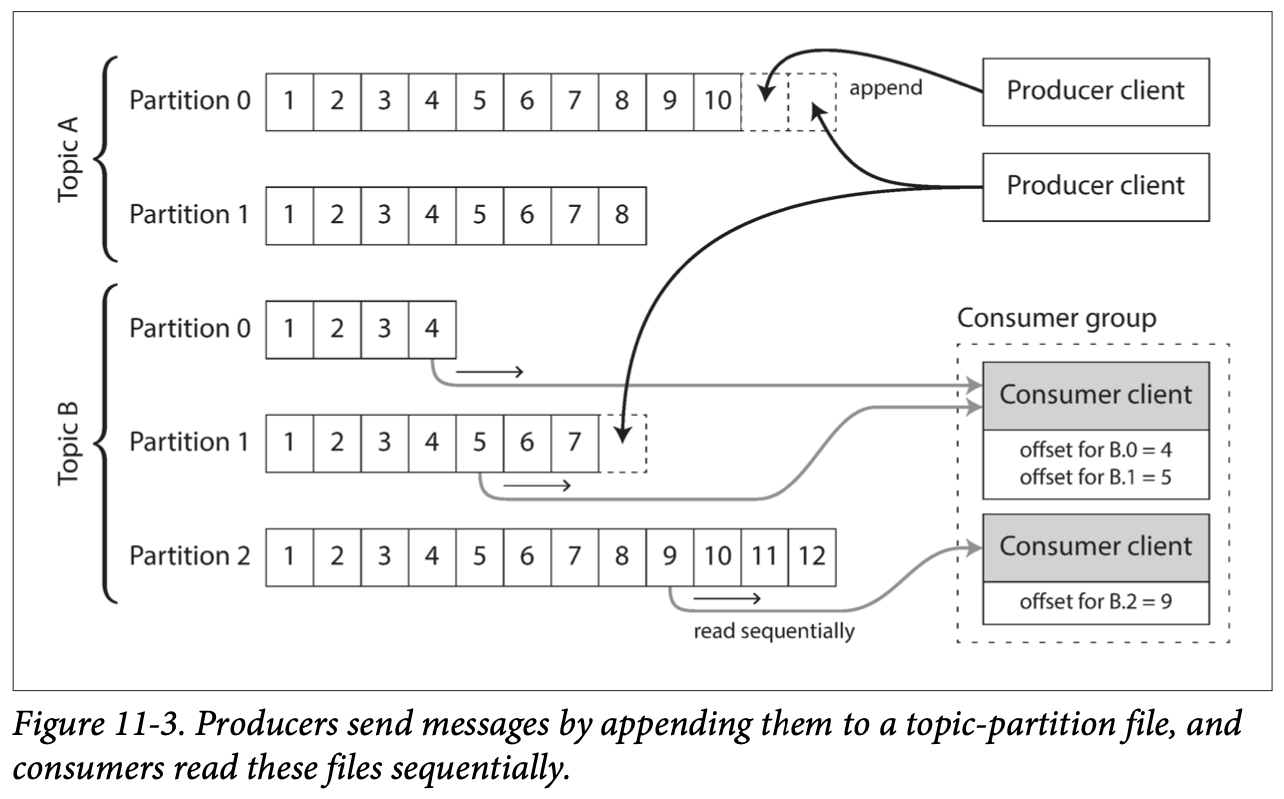
- 아파치 카프카, 아마존 키네시스 스트림, 트위터의 분산 로그 등
로그 방식 vs 전통적인 메시징 방식
- 로그 방식 : 처리량이 많고 메시지를 처리하는 속도가 빠르지만 메시지 순서가 중요
- JMS/AMQP 방식 : 메시지 처리 비용이 비쌈. 메시지 단위로 병렬화 처리. 메시지 순서 중요X
소비자 오프셋
- 소비자 오프셋 덕분에 브로커는 모든 개별 메시지마다 보내는 확인 응답 추적 불필요. 단지 주기적으로 소비자 오프셋 기록.
- 소비자 노드 장애 발생 시 : 소비자 그룹 내 다른 노드에 해당 파티션 할당 -> 마지막 기록된 오프셋부터 메시지 처리
- 장애가 발생한 소비자가 처리, but 아직 오프셋 기록 못한 메시지 : 두 번 처리됨
디스크 공간 사용
원형 버퍼(링 버퍼)
- 로그는 크기가 제한된 버퍼로 구현하고 버퍼가 가득 차면 오래된 메시지 순서대로 제거
- 메시지 보관 기관과 관계없이 모든 메시지를 디스크에 기록 => 로그 처리량 일정
- cf) 메시징 시스템 : 메모리에 메시지 유지, 큐가 너무 커질 때만 디스크에 기록. 큐가 작을 때는 빠름. 디스크 기록 시작 시 매우 느려짐. 즉, 보유한 메시지 양에 따라 처리량 다름.
소비자가 생산자를 따라갈 수 없을 때
선택할 수 있는 세 가지 방안 : 버리기, 버퍼링, 배압
로그 기반 방식은 버퍼링 형태.
소비자가 뒤처져 필요한 메시지가 디스크에 보유한 메시지보다 오래되면 필요한 메시지 읽기 불가.
- 특정 소비자가 너무 뒤처져도 다른 소비자에 영향 X
오래된 메시지 재생
AMQP/JMS 방식 메시지 브로커는 메시지 처리 확인 후 제거.
로그 기반 메시지 브로커는 로그를 변화시키지 않는 읽기 전용 연산. 부수 효과는 소비자 오프셋 이동만 발생. 소비자 오프셋은 조작 가능.
2. 데이터베이스와 스트림
데이터베이스에서의 이벤트 스트림 예시
- 복제 로그 : 리더는 DB 기록 이벤트 생산 -> 팔로워는 기록 스트림을 해당 DB 복제본에 기록
- 상태 기계 복제 : 모든 이벤트가 DB 쓰기를 나타내고 모든 복제 장비에서 같은 이벤트는 동일 순서로 처리. 복제 장비는 동일한 최종 상태로 끝남.
2.1 시스템 동기화 유지하기
요구사항 만족을 위해 여러 기술의 조합 사용. 관련이 있거나 동일한 데이터가 여러 다른 저장소에 저장되기 때문에 동기화가 필수.
주기적으로 데이터베이스 전체를 덤프하는 등으로 처리하기도 함.(일괄 처리) 이러한 방식이 너무 느린 경우 대안으로 이중 쓰기(dual write).
이중 쓰기
데이터가 변할 때마다 애플리케이션 코드에서 명시적으로 각 시스템에 기록
이중 쓰기의 문제점
- 경쟁 조건
- 클라이언트1: 값 A 쓰기 요청 -> 클라이언트2: 값 B 쓰기 요청
- DB 값은 B로 세팅
- 색인은 클라이언트2의 기록 -> 클라이언트1 순으로 봄
- 색임 값 A로 세팅
- 한쪽 쓰기가 성공할 때 다른 쪽 쓰기 실패 가능성 존재
- 내결함성 문제 : 동시 성공 또는 동시 실패를 보장하는 방식으로 원자적 커밋 문제
2.2 변경 데이터 캡처
데이터베이스에 기록하는 모든 데이터의 변화를 관찰해 다른 시스템으로 데이터를 복제할 수 있는 형태로 추출하는 과정
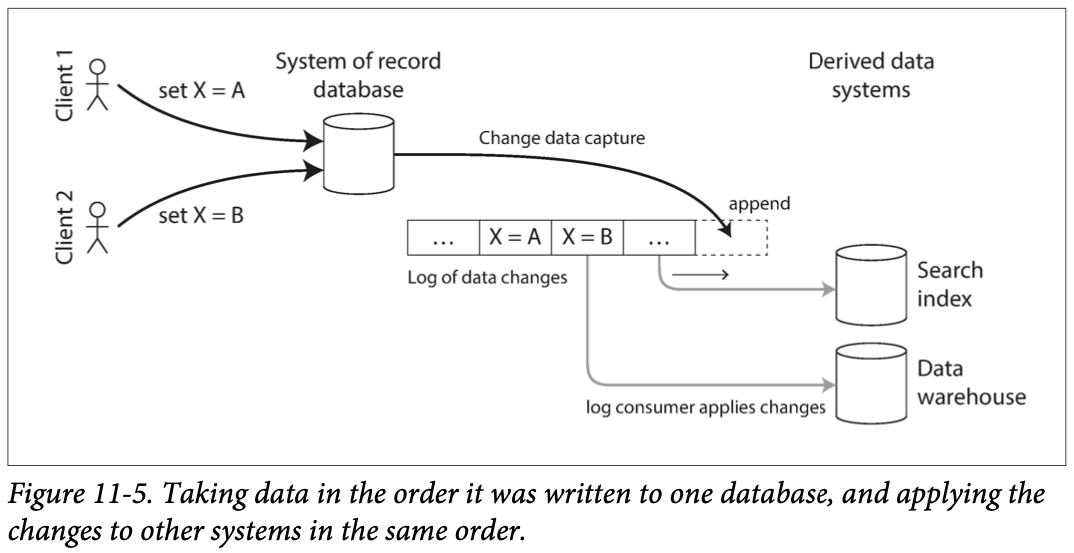
CDC 구현
CDC는 파생 데이터 시스템이 레코드 시스템의 정확한 데이터 복제본을 가지게 하기 위해 레코드 시스템에 발생하는 모든 변경 사항을 파생 데이터 시스템에 반영하는 것을 보장하는 메커니즘
변경 이벤트 전송에는 로그 기반 메시지 브로커 적합 : 메시지 순서를 유지하기 때문.
CDC는 비동기 방식으로 동작.
CDC는 복제 지연이 발생하는 단점이 있음.
CDC 구현에 사용되는 두 가지 방식
- DB 트리거
- 고장 나기 쉽고 성능 오버헤드 큼
- 복제 로그 파싱
- 스키마 변경 대응 등 필요
- 트리거 방식보다 견고한 방법
CDC 구현 상용 기술
링그드인의 Databus, 페이스북의 Wormhole, 야후의 Sherpa.
Maxwell과 Debezium은 binlog 파싱해 MySQL CDC 구현.
Mongoriver는 몽고DB의 oplog.
GoldenGate는 오라클용으로 제공.
초기 스냅숏
새로 구축하는 경우 전체 DB 복사본 필요. 최근 변경 사항만 반영만으로는 초기 구축 불가. 일관성 있는 스냅숏 사용.
데이터베이스 스냅숏은 변경 로그의 위치나 오프셋에 대응돼야 함. 그래야 스냅숏 이후 변경 사항 적용 시점 확인 가능.
로그 컴팩션
로그 히스토리 저장 limit 있을 경우 새로운 파생 데이터 시스템 추가 때마다 스냅숏 생성 필요. => 대안으로 로그 컴팩션.
- 원리 : 저장 엔진은 주기적으로 같은 키의 로그 레코드를 찾아 중복을 제거하고 각 키에 대해 가장 최근에 갱신된 내용만 유지.
- 로그 컴팩션 적용 시 컴팩션된 로그 토픽의 오프셋 0부터 시작해서 순차적으로 DB의 모든 키 스캔.
- CDC 원본 DB의 스냅숏 만들지 않고도 DB 콘텐츠 전체의 복사본 얻을 수 있음.
- Apache Kafka는 로그 컴팩션 기능 제공
변경 스트림용 API 지원
최근 DB들은 변경 스트림을 기본 인터페이스로서 지원하기 시작
- 리싱크DB(RethinkDB): 질의 결과에 변경이 있을 대 알림 받을 수 있게 구독이 가능한 질의 지원
- 파이어베이스(FireBase) & 카우치DB(CouchDB) : 애플리케이션에서도 사용 가능한 변경 피드 기반의 데이터 동기화 지원
- 미티어(Meteor) : 몽고DB의 oplog를 사용해 데이터 변경사항 구독하거나 사용자 인터페이스 갱신
- 볼트DB(VoltDB) : 스트림 형태로 데이터베이스에서 데이터를 지속적으로 내보내는 트랜잭션 제공
- Kafka Connect : 카프카를 광범위한 데이터 시스템용 CDC 도구로 활용 목적.
2.3 이벤트 소싱
DDD에서 개발한 기법으로, 애플리케이션 상태 변화를 모두 변경 이벤트 로그러 저장하는 방식.
CDC와의 차이점 : 추상화 레벨이 다름.
- CDC
- 변경 로그는 DB에서 저수준으로 추출.
- 애플리케이션은 CDC에 관심 X
- 이벤트 소싱
- 이벤트 로그에 기록된 불변 이벤트를 기반으로 애플리케이션 로직 구현
- 이벤트는 애플리케이션 수준에서 발생한 일을 반영
장점
- 데이터 모델링에 쓸 수 있는 강력한 기법
- 사용자의 행동을 불변 이벤트로 기록
- 디버깅에 도움
- 애플리케이션 버그 방지
이벤트 스토어(EventStore)같은 이벤트 소싱 특화 DB도 있지만, 일반적인 DB와 로그 기반 메시지 브로커 통한 구축도 가능.
이벤트 소싱을 사용하는 애플리케이션은 시스템에 기록한 데이터를 표현한 이벤트 로그를 가져와 사용자에게 보여주기에 적당한 애플리케이션 상태로 변환.
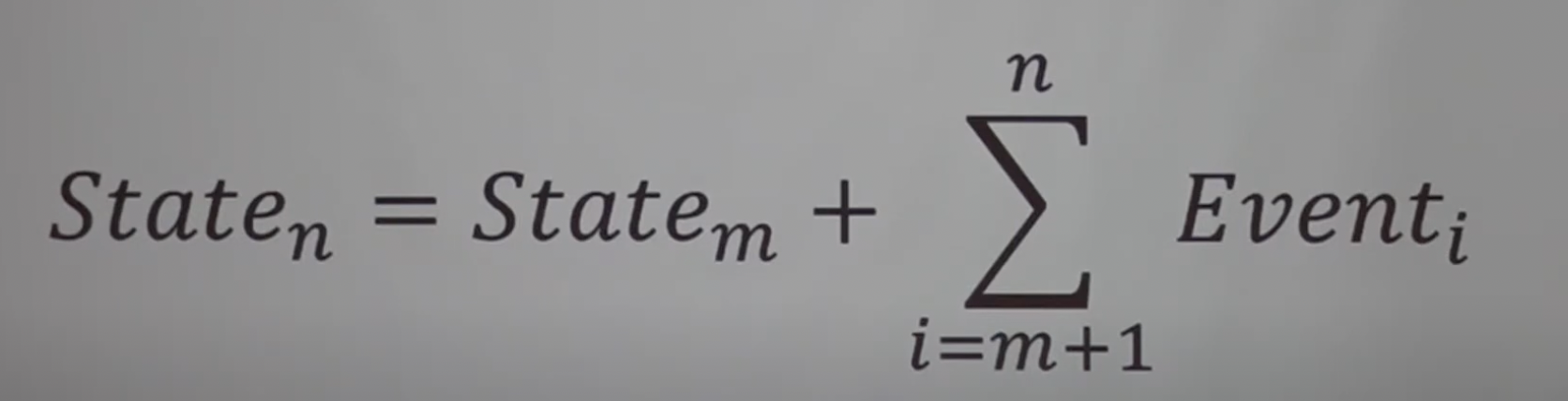
Command VS Event
- Command : 사용자 등의 특정 행위에 대한 요청
- Event : 도메인 변경에 대한 사실
2.4 상태와 스트림 그리고 불변성
DB는 애플리케이션의 현재 상태 저장.
애플리케이션 상태 = 시간에 따른 이벤트 스트림의 적분
변경 스트림 = 시간으로 상태를 미분
변경 로그를 지속성 있게 저장한다면 상태를 간단히 재생성 가능.
불변 이벤트 장점
- 버그 발생 시 진단과 복구 쉬움
- 현재 상태보다 훨씬 많은 정보
동일한 이벤트 로그로 여러 가지 뷰 만들기
- 불변 이벤트 로그에서 가변 상태를 분리하면 동일한 이벤트 로그로 다른 여러 읽기 전용 뷰 만들 수 있다.
- CQRS 가능 : 데이터 쓰기와 읽기 형식의 분리.
동시성 제어
이벤트 소싱과 CDC의 가장 큰 단점은 이벤트 로그의 소비가 대개 비동기
사용자가 로그에 이벤트 기록 -> 이어서 로그에서 파생된 뷰 읽기 : 이벤트가 아직 읽기 뷰에 미반영(자신이 쓴 내용 읽기 문제)
동시성 제어 해결책
- 읽기 뷰의 갱신과 이벤트 추가 작업 동기식 수행
- 하나의 트랜잭션으로 묶어야 함. 다른 시스템인 경우 분산 트랜잭션 필요. 또는 전체 순서 브로드캐스트를 사용해 선형성 저장소 구현하기(347p.)
- 이벤트 로그로 현재 상태 만들기
- 이벤트를 로그에 추가만 하면 되어 원자적으로 만듦.
- 이벤트 로그와 애플리케이션 상태를 같은 방식으로 파티셔닝
- 단일 스레드 로그 소비자는 쓰기용 동시성 제어 불필요
불변성 한계
- 성능 이슈
- 모든 변화의 불변 히스토리 유지는 언제까지 가능?
- 컴팩션 & GC의 성능 문제
- 불가피한 데이터 삭제
- 개인정보 등의 사유로 삭제 필요한 경우 존재
- 히스토리를 새로 쓰고 문제가 되는 데이터를 처음부터 기록하지 않았던 것처럼 처리 필요 : 데이토믹의 적출(exicision), 포씰 버전 관리 시스템의 셔닝(shunning) 개념
3. 스트림 처리
스트림 처리 방법 세 가지
- 다른 저장소 시스템에 기록
- 사용자에 직접 보냄
- 하나 이상의 입력 스트림 처리해 하나 이상의 출력 스트림 생산
- 스트림을 처리하는 코드 조각 :
연산자또는작업이라고 부름
- 스트림을 처리하는 코드 조각 :
일괄 처리 작업과 스트림의 다른 점은 끝나지 않음
- 정렬 병합 조인 사용 불가
- 일괄 처리와는 다른 내결함성 메커니즘 필요
3.1 스트림 처리의 사용
1) 복잡한 이벤트 처리(complex event processing, CEP)
특정 이벤트 패턴을 검색해야 하는 애플리케이션에 특히 적합
스트림에서 특정 이벤트 패턴을 찾는 규칙 규정 가능
CEP 엔진 작동 방식 : 질의를 오랜 기간 저장하고 입력 스트림으로부터 들어오는 이벤트는 지속적으로 질의를 지나 흘러가면서 이벤트 패턴에 매칭되는 질의를 찾는 방식
2) 스트림 분석
대량의 이벤트를 집계하고 통계적 지표를 추출
활용 예시
- 특정 유형의 이벤트 빈도 측정
- 특정 기간 걸친 값의 이동 평균 계산
- 이전 시간 간격과 현재 통계값의 비교
일반적으로 이런 통계는 고정된 시간 간격 기준으로 계산.
집계 시간 간격을 윈도우라고 함.
스트림 분석 시스템은 블룸 필터, 하이퍼로그로그, 백분위 추정 알고리즘 등의 확률적 알고리즘 사용하기도 함.
아파치 스톰, 스파크 스트리밍, 플링크, 콩코드, 쌈자, 카프카 스트림 등
3) 구체화 뷰 유지
파생 데이터 시스템
- 스트림을 통해 캐시, 검색 색인, 데이터 웨어하우스 등의 파생 데이터 시스템이 원본 DB의 최신 내용을 따라 잡음.
이벤트 소싱
- 애플리케이션 상태는 일종의 구체화 뷰
쌈자, 카프카 스트림은 카프카의 로그 컴팩션 기능 기반 구체화 뷰 유지 용도 사용 가능
4) 스트림 상 검색
복수 이벤트로 구성된 패턴은 찾는 CEP와 달리, 전문 검색 질의와 같은 복잡한 기준을 기반으로 개별 이벤트 검색
5) 메시지 전달과 RPC
메시지 전달 시스템을 RPC 대안으로 사용.
아파치 스톰의 분산 RPC : 이벤트 스트림을 처리하는 노드 집합에 질의를 맡김. 질의는 입력 스트림 이벤트가 끼워지고 그 결과들을 취합해 사용자에게 돌려줌.
3.2 시간에 관한 추론
스트림 처리 프레임워크는 윈도우 시간을 결정할 때 처리하는 장비의 시스템 시계를 이용. 간단하다는 장점이 있으나, 이벤트가 실제로 발생한 시간보다 처리 시간이 많이 늦어지면 문제 발생.
- 처리 시간 기준 이벤트 처리 시 문제점 : 이벤트 스트림에 대한 처리 결과가 실제와 차이 발생
- 이벤트 시간 기준 : 특정 윈도우에서 모든 이벤트가 도착했다거나 아직도 이벤트가 계속 들어오고 있는지 확신 불가
- 네트워크 중단으로 일부 이벤트가 버퍼링되어 있을 가능성 존재
- 낙오자 이벤트 처리 방법 두 가지
- 무시
- 수정 값 발행
사용자가 제어하는 장비의 시계는 어뷰징 가능성 존재로 신뢰도 낮음.
서버 시계는 이벤트를 서버에서 받은 시각은 정확하나 사용자와의 상호작용 설명하기에는 부족.
잘못된 장치 시계 조정 방법 : 세 가지 타임스탬프 로그로 남김.
- 이벤트가 발생한 시간 : 장치 시계를 따름
- 이벤트를 서버로 보낸 시간 : 장치 시계
- 서버에서 이벤트를 받은 시간 : 서버 시계
윈도우 유형
윈도우는 이벤트 수를 세거나 윈도우 내 평균값을 구하는 등 집계할 때 사용
- 텀블링 윈도우
- 윈도우 크기 : 고정 길이
- 모든 이벤트는 정확히 한 윈도우에 속함
- 홉핑 윈도우
- 고정 길이
- 윈도우 중첩
- eg) Hopping(10min, 5min) : 0min - 10min, 5min - 15min, …
- 슬라이딩 윈도우
- 각 시간 간격 사이에서 발생한 모든 이벤트 포함
- 시간 기준으로 정렬한 이벤트를 버퍼에 유지하고 오래된 이벤트 만료 시 윈도우에서 제거 방식으로 구현
- 세션 윈도우
- 고정된 기간 X
- 같은 사용자가 짧은 시간동안 발생시킨 모든 이벤트를 그룹화
3.3 스트림 조인
1) 스트림 스트림 조인(윈도우 조인)
- 검색 결과에 대한 클릭율 : 검색 이벤트 + 클릭 이벤트 모두 필요
- 조인을 위한 적절한 윈도우 선택 (eg. 한 시간 이내 발생한 검색과 클릭을 조인)
- 조인 구현을 위해 스트림 처리자가
상태유지 필수.- 모은 이벤트 세션 ID로 색인. 이벤트 발생 때마다 색인 추가. 다른 이벤트 있는지 다른 색인 확인. 이벤트 매칭 시 검색한 결과 클릭 확인 이벤트 발행. 매칭 X 경우 검색 결과 클릭되지 않았음 확인 이벤트 발행.
2) 스트림 테이블 조인(스트림 강화)
- 모은 이벤트 세션 ID로 색인. 이벤트 발생 때마다 색인 추가. 다른 이벤트 있는지 다른 색인 확인. 이벤트 매칭 시 검색한 결과 클릭 확인 이벤트 발행. 매칭 X 경우 검색 결과 클릭되지 않았음 확인 이벤트 발행.
강화: 데이터베이스의 정보로 이벤트에 정보 추가- 스트림 처리는 한 번에 하나의 활동 이벤트를 대상으로 DB에서 정보 찾아 이벤트에 추가
- 원격 질의는 느리고, DB 과부화 위험 => 로컬에서 질의 가능하도록 스트림 처리자 내부 DB 사본 적재
- DB의 로컬 복사본 최신 상태 유지 위해 CDC 사용. : 이벤트 + 변경 데이터 스트림 두 개의 스트림 조인
- 스트림 스트림 테이블과 유사하나 차이점 존재
- 스트림 테이블 조인
- 테이블 변경 로그 스트림 : 시작 시간까지 이어지는 윈도우 사용. 레코드의 새 버전으로 오래된 것을 덮어씀.
- 스트림 입력 : 윈도우 전혀 유지 않을 수도 있음.
- 스트림 테이블 조인
3) 테이블 테이블 조인 (구체화 뷰 유지)
트위터 타임라인 예제 : 트윗과 팔로우 관계에 따른 타임라인 데이터 관리.
트윗과 팔로우, 두 테이블을 조인하는 질의 구체화 뷰를 유지하는 방식.
조인 테이블이 변할 때마다 갱신.
조인 시간 의존성
세 유형 모두 스트림 처리자가 하나의 조인 입력을 기반으로 한 특정 상태(eg. 검색, 클릭 이벤트, 사용자 프로필, 팔로워 목록)를 유지해야 하고 다른 조인 입력에서 온 메시지에 그 상태를 질의. 상태 유지에 있어 이벤트의 순서는 중요.
데이터 웨어하우스의 천천히 변하는 차원(slowly changing dimension, SCD) : 복수 개의 스트림에 걸친 이벤트 순서가 결정되지 않으면 조인도 비결정적.
- 해결법 : 조인되는 레코드의 특정 버전을 가리키는 데 유일한 식별자 사용
- 테이블에 있는 레코드의 모든 버전 보유 필수 : 로그 컴팩션 불가
3.4 내결함성
스트림은 무한하고 처리를 완료하는 것이 불가하기 때문에 일괄 처리 방식과는 다름.
마이크로 일괄 처리 & 체크포인트
마이크로 일괄 처리
- 스트림을 작을 블록으로 나누고 각 블록을 소형 일괄 처리와 같이 다루는 방법
- 스파크 스트리밍
- 일괄 처리 크기
- 큼 : 스트림 처리 결과 확인 시간 지연
- 작음 : 스케쥴링, 코디네이션 비용 증가
- 일괄 처리 크기와 동일한 크기 텀블링 윈도우 암묵적 지원
체크포인트
- 주기적으로 상태의 롤링 체크포인트를 생성하고 지속성 있는 저장소에 저장. 스트림 연산자에 장애 발생 시 스트림 연산자는 가장 최근 체크포인트에서 재시작, 해당 체크 포인트와 장애 발생 사이의 출력 버림.
- 아파치 플링크
두 가지 방식 모두 출력이 한 번 처리되는 정확히 한 번 시맨트 지원. 다만 출력 발생 후 스트림 처리자 떠나자마자 출력 결과 지울 수 없음.
실패 테스크 재실행 시 외부 부수 효과 두 번 발생.
원자적 커밋 재검토
장애 발생 시 정확히 한 번 처리되는 것처럼 보일려면 처리가 성공했을 때만 모든 출력과 이벤트 처리의 부수 효과가 발생하게 해야 함.
구글 클라우드 데이터플로, 볼트 DB에서 원자적 커밋 구현 활용. 아파치 카프카도 예정.
- 이기종 간 트랜잭션 지원 X
- 스트림 처리 프레임워크 내 상태 변화와 메시지를 관리해 트랜잭션을 내부적으로 유지
멱등성
여러 번 수행하더라도 오직 한 번 수행한 것과 같은 효과
멱등 연산은 정확히 한 번 시맨틱을 당성하는 데 적은 오버헤드만 드는 효율적 방법
실패 후에 상태 재구축
상태가 필요한 스트림 처리는 실패 후 해당 상태 복구 보장 필수.
- 원격 데이터 저장소에 상태 유지, 복제 : 느리다는 단점
- 스트림 처리자의 로컬에 상태를 유지하고 주기적 복제
입력 스트림을 사용해 재구축 가능한 경우 상태 복제 불필요.
