[Java] HashMap vs TreeMap
HashMap vs TreeMap 비교
Map 이란?
- key-value 형식의 데이터를 저장할 수 있는 자료구조.
- Map의 구현체로 java.util 패키지 내
HashMap,TreeMap,LinkedHashMap,HashTable,EnumMap이 있으며, 그 외 패키지에 다양한 구현체들이 있음.
🚀HashMap
- Key를 해시 함수를 이용해 저장하여 빠르게 처리
- 입력과 삭제에 대한 시간복잡도가
O(1)인 자료구조
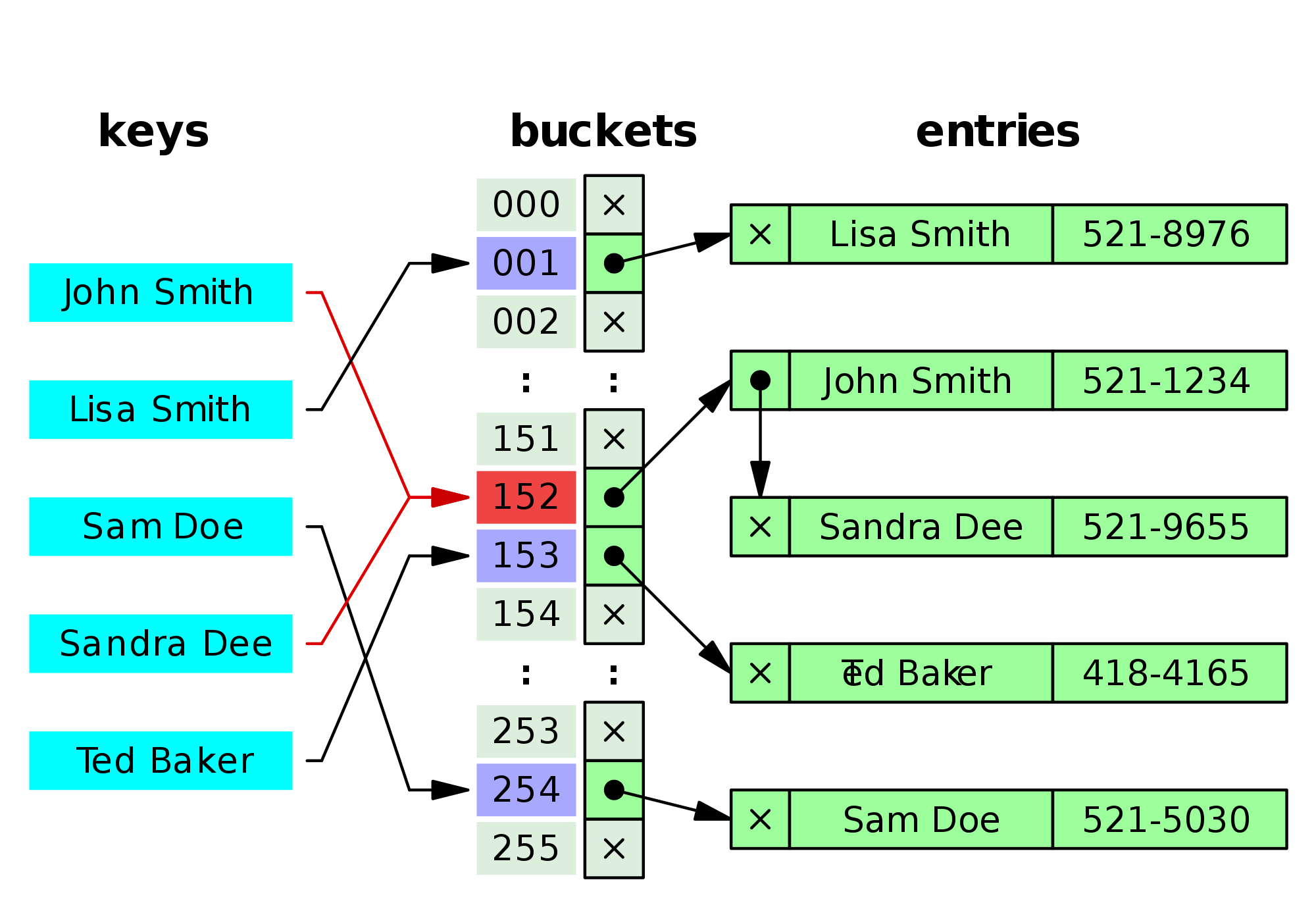
💻Hash Map의 작동 방식
각 객체의 hashCode() 메서드가 반환하는 int 값을 사용. hash 값이 겹치는 경우가 발생하는데 이를 해시 충돌이라고 한다.
해시 충돌이 발생하더라도 데이터를 저장하고 조회할 수 있게 하는 방식으로 Open Addressing과 Seperate Chaining의 두 가지가 있다.
- Open Addressing
- 데이터를 삽입하려는 해시 버킷이 이미 사용 중인 경우 다른 해시 버킷에 해당 데이터를 삽입하는 방식
- 데이터를 저장/조회할 해시 버킷을 찾을 때는 Linear Probing, Quadratic Probing 등의 방법을 사용
- Separate Chaining
- 각 배열의 인자는 인덱스가 같은 해시 버킷을 연결한 링크드 리스트의 첫 부분(head)
💻시간복잡도
- 둘 다 Worst Case :
O(M) - Open Addressing은 연속된 공간에 데이터를 저장하기 때문에 Separate Chainig에 비해 캐시 효율 높음
- 데이터 개수가 충분히 적다면
Open Addressing이 Separate Chaining보다 성능 좋음
💻HashMap은 Separate Chaining방식 사용. Why?
- 데이터 삭제에 있어서 더 장점이 있기 때문.
- 키-값 쌍 개수가 일정 개수 이상으로 많아지면 Open Addressing보다 빠름
- Open Addressing의 경우 해시 버킷을 채운 밀도가 높아질수록 Worst Case 발생 빈도가 더 높아지기 때문
💻Java 8 HashMap에서의 Separate Chaining
Java 8 부터는 데이터의 개수가 많아지면 Separate Chaining에서 링크드 리스트 대신 트리를 사용.
링크드 리스트와 트리 사용의 기준은 하나의 해시 버킷에 할당된 키-값 쌍의 개수.
트리는 Red-Black Tree를 사용. 자바 콜렉션 프레임워크의 TreeMap과 구현 거의 동일.
💻해시 버킷 동적 확장
HashMap은 키-값 쌍 데이터 개수가 일정 개수가 이상이 되면, 해시 버킷의 개수를 두 배로 늘림. 이렇게 해시 버킷 개수를 늘리면 값도 작아져, 해시 충돌로 인한 성능 손실 문제를 어느 정도 해결 가능.
해시 버킷 개수의 기본값은 16, 데이터 개수가 임계점에 이를 때마다 해시 버킷 개수의 크기를 두 배씩 증가함.
HashMap에 저장될 데이터 개수가 어느 정도인지 예측 가능한 경우에는 이를 생성자의 인자로 지정하면 불필요하게 Separate Chaining을 재구성하지 않게 할 수 있음.
임계치의 경우 0.75이 기본값이나, 직접 설정할 수도 있음.
- 자바 스프링에서 성능을 위해 해시 버킷 개수를 지정하는 경우가 있음.
public enum HttpMethod {
GET, HEAD, POST, PUT, PATCH, DELETE, OPTIONS, TRACE;
private static final Map<String, HttpMethod> mappings = new HashMap<>(16);
// ... 이하 생략
}
🚀TreeMap
내부의 값들을 Key 값을 기준으로 정렬해 가지고 있음. 정렬된 순서를 알 수 없는 HashMap과 차이가 있음.
내부에서 Red-Black Tree 자료구조를 이용.
