[etc] 데이터 해방
이벤트 기반 마이크로 서비스 구축(애덤 벨메어 지음)의 데이터 해방 개념 정리
1. 데이터 해방?
이벤트 기반 마이크로서비스로 전환하려면 먼저 이벤트 브로커에 있는 비즈니스 도메인 데이터를 이벤트 스트림으로 소비할 수 있도록 놓아주어야 함.
데이터가 포함된 기존 시스템 및 상태 저장소에서 데이터를 소싱하는 데이터 해방 프로세스.
1.1 데이터 해방이란?
데이터 해방은 교차 도메인 데이터 세트(cross-domain data set)를 식별해서 각 이벤트 스트림에 발행하는, 이벤트 기반 아키텍처의 마이그레이션 전략의 일부분.
데이터 해방의 목표 : 조직의 중요한 데이터가 깨끗하고 일관되게 담긴 단일 진실 공급원을 제공.
데이터 접근 행위가 데이터 생상/저장하는 행위와 분리 → 두가지 일을 모두 수행하는 통신 구조 구현할 필요 ❌
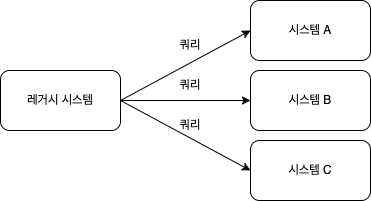
데이터 해방 적용 전
데이터 해방 적용 후

1.1.1 데이터 해방 시 고려 사항
데이터 세트와 해방 된 이벤트 스트림의 완전한 동기화
- 동기화의 요건은
최종 일관성(결과적으로 일관성이 맞춰지는 속성. 어느 시점에는 일관성이 일치하지 않을 수 있음)
1.2. 데이터 해방 패턴
- 쿼리 기반
- 하부 데이터 저장소를 쿼리해서 데이터 추출
- 어떤 종류의 데이터 저장소든 작업 가능
- 로그 기반
- 하부 데이터 구조의 변경 내역을 기록한 붙임 전용 로그 기준으로 데이터 추출
- 데이터 변경 로그를 보관하는 데이터 저장소(MySQL, PostgreSQL 등)에서만 가능한 방법
- 테이블 기반
- 출력 큐로 사용할 테이블에 데이터 푸시. 다른 스레드나 별도의 프로세스가 테이블을 쿼리해 데이터를 정해진 이벤트 스트림으로 내보낸 뒤 관련 엔트리 삭제
- 데이터 저장소가 트랜잭션 및 출력 큐 메커니즘을 모두 지원할 경우에만 가능
⭐️세 패턴 모두 소스 레코드의 최근 업데이트 시간(updated_at) 컬럼을 이용해 이벤트를 타임스탬프 순서대로 생산해야 한다!
1.2.1 쿼리 기반
1.2.1.1 쿼리 기반 업데이터 장점
맞춤성(customizability)
- 모든 데이터 저장소 쿼리 가능
- 클라이언트가 쿼리 옵션 지정 가능
독립적인 폴링 주기
- SLA(서비스 수준 협약?)가 엄격한 쿼리는 실행 빈도를 높이고, 그밖의 비용이 많이 드는 나머지 쿼리는 빈도를 낮추는 식으로 리소스 절약 가능
내부 데이터 모델의 격리
- RDB에서는 materialized view 또는 view 객체를 이용해 내부 데이터 모델과 분리 가능
- 데이터 저장소 외부로 노출돼선 안 되는 도메인 모델 정보를 숨기고자 사용하는 기법
1.2.1.2 쿼리 기반 업데이터 단점
최종 업데이트 시간 타임스탬프가 필수
- 쿼리할 하부 테이블 또는 이벤트의 namespace에 최종 수정 시간 타임스탬프가 반드시 존재해야
- 데이터가 마지막으로 업데이트된 시간에 따라 증분 업데이트를 하는 방식이기 때문에 필수 칼럼
하드 삭제 추적 불가
- 하드 삭제는 쿼리 결과에 포함 X
- 삭제 여부 같은 불리언 컬럼을 이용하는 플래그 기반의 소프트 삭제만 가능
데이터 세트 스키마, 출력 이벤트 스키마 간의 취약한 의존 관계
간헐적 캡처
- 레코드에 대한 일련의 변경들은 각자 개별적인 이벤트로만 보임
생산 리소스 낭비
- 쿼리 실행으로 인한 리소스 낭비
데이터 변경 때문에 쿼리 성능이 오르락내리락
- 최악의 경우, 데이터 경함 발생할 수 있음
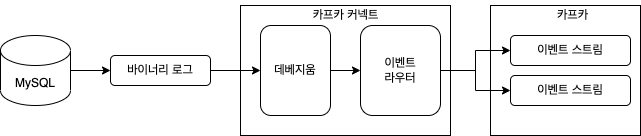
1.2.2 CDC 로그 기반
데이터 저장소에 내장된 CDC 로그 기능 활용하는 방법
변경분에 대한 로그에서 데이터를 소싱하는 방법은 Debezium이 유명
- Debezium을 사용하면 간단한 설정만으로 아파치 카프카에 레코드 생산 가능
1.2.2.1 CDC 로그 장점
삭제 추적
- 바이너리 로그에 하드 레코드 삭제 포함
데이터 저장소 서능에 미치는 영향 최소화
- 성능에 별 영향 없이 CDC 작업 수행 가능
- SQL 서버의 경우처럼 변경 테이블을 사용한다면 데이터량만큼 영향
저지연 업데이트
- 이벤트가 로그에 기록되면 곧바로 업데이트 전파 → 다른 데이터 해방 패턴보다 지연 시간 짧음
1.2.2.2 CDC로그 단점
내부 데이터 모델 노출
- 쿼리 기반의 업데이트에서 뷰를 격리 수단으로 사용하는 것과 달리, 내부 데이터 모델일 체인지로그에 완전히 노출
- 내부 데이터 모델을 신중하게 선별하여 격리할 필요
데이터 저장소 외부에서 반정규화
- 체인지로그에는 이벤트 데이터만 존재 → 데이터 저장소 외부에서 반정규화 발생
데이터 세트 스키마와 출력 이벶ㄴ트 스키마 사이의 취약한 의존 관계
- 데이터 저장소 애플리케이션 외부에 존재 : 데이터 세트 변경, 필드 타입 재정의 등 유효한 데이터 저장소의 변경 발생 시 기존 이벤트 스키마와 어긋날 가능성 존재
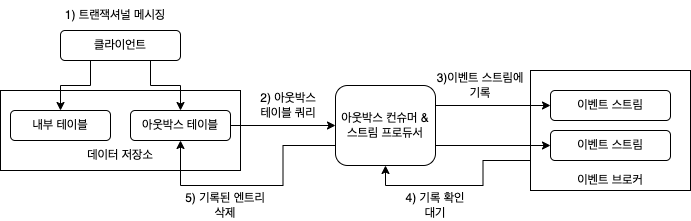
1.2.3 아웃박스 테이블 기반
아웃박스 테이블에는 데이터 저장소의 내부 데이터에 관한 중요한 업데이트가 로우 단위로 삽입됨. CDC 대상으로 표시된 데이터 저장소에서 테이블 레코드가 삽입, 수정, 삭제될 때마다 해당 레코드가 아웃박스 테이블에 발행되는 구조. CDC하는 테이블 마다 자체 아웃박스 테이블을 두거나, 모든 변경분을 하나의 아웃박스 테이블에 기록.
내부 테이블의 업데이트와 아웃박스 테이블의 업데이트는 단일 트랜잭션
1.2.3.1 아웃박스 테이블 장점
다수의 언어 지원
- 트랜잭션 기능을 제공하는 클라이언트/프레임워크 어느 것이라도 사용 가능
사전 스키마 강화
- 아웃박스 테이블에 삽입하기 전에 직렬화함으로써 스키마가 올바른지 확인 가능
내부 데이터 모델 격리
- 데이터 저장소 애플리케이션 개발자가 아웃박스 테이블의 어느 필드에 쓸지 선택 가능
반정규화
- 아웃박스 테이블에 쓰기 전에 데이터를 필요한 만큼 반정규화 가능
1.2.3.2 아웃박스 테이블 단점
애플리케이션 코드 변경 필수
비즈니스 프로세스 성능에 영향
- 직렬화를 통해 스키마 유효성을 검증할 때 성능에 영향을 줄 가능성 존재
- 트랜잭션 실패 시 비즈니스 작업도 더 이상 진행 불가
데이터 저장소 성능에 영향
